



Sudama Prasad
Cloud Platform Engineering Lead at Glencore UK
Deep learning has soared in popularity, enabling breakthroughs in fields like image recognition and language modelling, as highlighted in the Stanford AI Index 2023. Yet this progress comes with hefty financial demands.
Some estimates suggest that cloud GPU costs have risen significantly over the past year, a leap that can overwhelm smaller teams or research labs. Hidden fees for data storage, network transfers, and model optimization further inflate the bill, especially since many AI workflows function like black boxes, making it hard to track whether GPU hours are truly necessary or simply idle.
This is where FinOps – an operational framework for maximizing business value through iterative optimization and cross-functional collaboration – proves critical. FinOps helps manage costs while maintaining top-tier model accuracy.
This paper applies to FinOps teams managing public cloud costs who have been asked to additionally manage technology spending and usage for AI.
An existing understanding of the FinOps Framework Domains and Capabilities for public cloud.
If there’s a single elephant in the room when it comes to deep learning costs, it’s GPU usage. Teams often spin up GPU clusters just in case they need extra processing power, only to watch them idle for hours—or even days. This over-provisioning is understandable since nobody wants to be stuck waiting for GPU availability while a critical experiment is scheduled, but in practice, it wastes money.
A quick example from a financial analytics startup: They provisioned eight high-end GPUs for their forecasting models. Turned out, half of these GPUs sat idle roughly 40% of the time. That may not seem like a big deal in the short run, but over the span of months, the unnecessary cost skyrocketed.
Example GPU Over-Provisioning Scenario
| Resource | Provisioned | Average Utilization | Idle Percent | Estimated Monthly Cost |
|---|---|---|---|---|
| GPU Cluster A | 8 GPUs | 60% | 40% | $12,000 |
| GPU Cluster B | 4 GPUs | 70% | 30% | $5,500 |
| GPU Cluster C | 2 GPUs | 90% | 10% | $2,000 |
(Note: These figures were sourced from a real-world implementation but are anonymized for compliance and security reasons.)
Not surprisingly, the more advanced or specialized the GPU, the higher the cost impact of leaving it unused. If you’ve got top-tier A100 or H100 GPUs sitting around, that’s burning a serious hole in your cloud budget.
To address these inefficiencies, tools like NVIDIA’s Data Center GPU Manager (DCGM) or Kubernetes Resource Metrics can be employed for real-time monitoring of GPU utilization. These tools help teams identify underutilized resources and take corrective action promptly.
Additionally, platforms like Run:AI or Weights & Biases enable dynamic GPU allocation based on workload demand, ensuring optimal usage. For example, deploying Run:AI automatically reassigns idle GPUs to new training jobs in real time.
Deep learning involves heaps of data—images, text, audio clips, or some combination of them all. Storing and moving this data can be a sneaky cost culprit. Large datasets require not just storage capacity but also careful orchestration of how (and where) they’re accessed.
Imagine you’re working in a multi-cloud setup: your model is training on Platform A, but your data is sitting in Platform B. Each time you fetch data across regions, you incur a transfer fee. Even if it’s just a few cents per gigabyte, repeated tens of thousands of times can pile up. Similarly, storing data redundantly just in case might be convenient from a DevOps perspective but detrimental for your budget.
Another major cause of deep learning cost overruns is poor monitoring. Teams often rely on a single metrics dashboard for GPU usage or memory consumption, but they rarely factor cost in real-time. A job might be running at 80% GPU utilization, which sounds good, but if the job is incorrectly configured or running for far too long, it’s effectively racking up unnecessary costs.
Similarly, forecasting for deep learning projects can be unpredictable. Sprints sometimes run over, or new feature engineering tasks pop up. If cost forecasting is purely guesswork—like “we’ll probably need 30 GPU hours this month” — chances are your actual usage will differ significantly. By ignoring real-time adjustments, you risk underestimating or overestimating your budget, leading to end-of-month billing sticker shock.
By coupling real-time monitoring with advanced forecasting, you can transform cost management from a reactive process into a proactive one.
FinOps starts with clarity. You can’t optimize what you can’t see., right? The FinOps Framework Inform Phase is all about getting a granular view of every cost driver in your deep learning pipeline:
By mapping out these stages, you’ll start to see hotspots of resource consumption. Maintain a Cost Map for deep learning workflows—it’s essentially a flowchart that highlights each step’s estimated monthly cost. FinOps tools and cloud service provider tools like AWS Cost Explorer or Azure Monitor can simplify creating such a Cost Map by providing granular insights into resource usage.
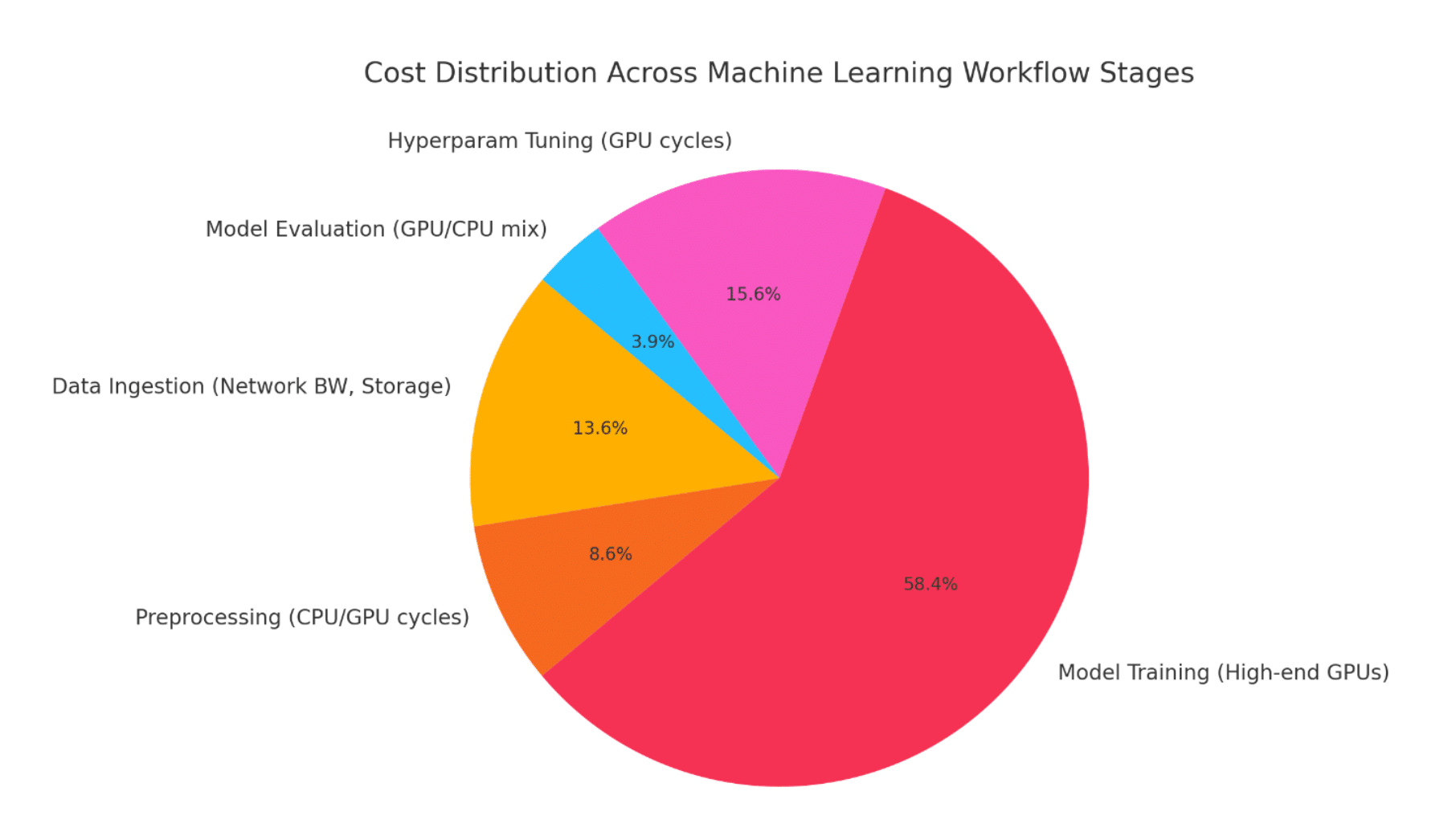
Sample Deep Learning Cost Map
| Workflow Stage | Primary Resource(s) | Estimated Monthly Cost |
Observations |
|---|---|---|---|
| Data Ingestion | Network BW, Storage | $3,500 | 2.5 TB inbound monthly, heavy spikes |
| Preprocessing | CPU/GPU cycles | $2,200 | CPU usage at 65%, GPU usage at 35% |
| Model Training | High-end GPUs | $15,000 | Most costly stage (80% of budget) |
| Hyperparam Tuning | GPU cycles | $4,000 | Bayesian optimization in use |
| Model Evaluation | GPU/CPU mix | $1,000 | Lower compute but frequent sweeps |
(Note: These figures were sourced from a real-world implementation but are anonymized for compliance and security reasons.)
After you’ve got a clear baseline, it’s time to Optimize. This phase is where you look at each cost driver and figure out how to reduce it without killing productivity or accuracy.
The final FinOps Phase, Operate, is all about embedding these cost-saving habits into your team’s daily workflow. The best cost dashboard in the world is worthless if your data scientists and finance folks only glance at it once a quarter.
Ensuring Consistent Collaboration:
To ensure cross-functional teams stay aligned, consider embedding cost metrics into team performance reviews or project retrospectives. This way, finance teams gain a deeper understanding of the complexities of AI workloads, while AI engineers learn to speak the language of cost and budgeting.
While not widespread yet, GPU quorum allocation is a strategy worth mentioning. In essence, you set a quorum threshold—meaning you only allocate GPU resources if a job is likely to use them above a certain utilization (e.g., 70%). This helps prevent those annoying half-idle scenarios where a training job occupies a GPU but only uses 30% of its capacity.
Some HPC frameworks like Slurm or HTCondor can be tweaked to do this sort of advanced scheduling. It’s not a magic bullet, but for teams consistently underutilizing their GPUs, it can yield meaningful savings. See the documentation for Slurm and HTCondor.
Containerization for microservices if a familiar architecture pattern, but what about super-modular data flows for deep learning? Instead of a monolithic pipeline that preps data in giant chunks, consider breaking it into smaller steps that spin up compute resources for brief intervals. For example:
This approach might require more orchestration effort up front, but it slashes idle time drastically. And yes, ephemeral HPC clusters can be a headache to configure—but once set up, they pay off through automatic cost scaling.
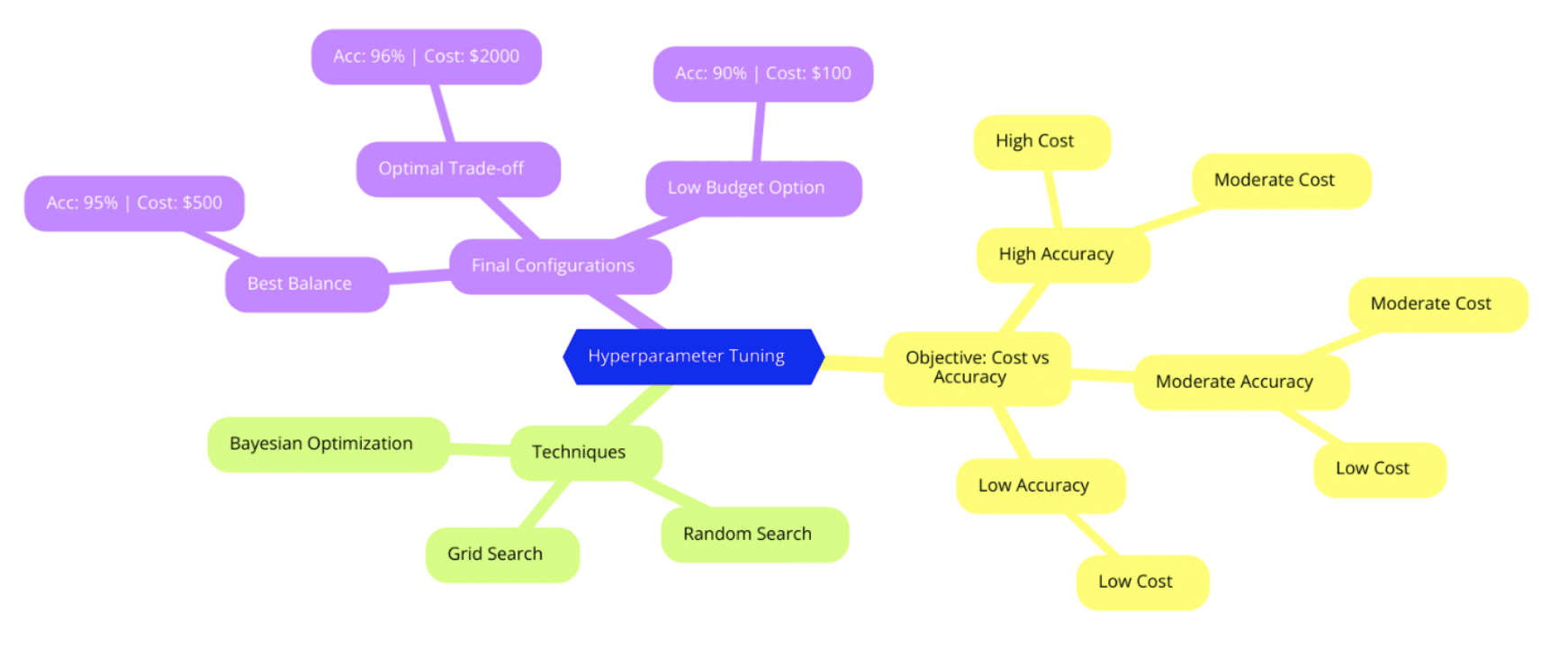
Think about hyperparameter optimization as a multi-objective problem. Typically, you optimize for accuracy or F1 score, but why not also factor in cost or time constraints? A technique sometimes called Multi-Objective Bayesian Optimization can weigh these variables.
For instance, if your model hits 95% accuracy at $500 in compute costs, but 96% accuracy takes $2,000, you might decide it’s not worth the extra expense. This is especially relevant for startups or research institutions with strict budget caps. While cost-based tuning is still somewhat niche, it’s gaining momentum as organizations recognize the financial (and environmental) impact of unnecessarily large training cycles.
Below is a quick snapshot of emerging trends that could reshape how deep learning teams handle costs and operations in the years ahead. While some of these ideas might sound a bit speculative, they’re already bubbling up in early R&D circles. If even a portion of these predictions pan out, they’ll have notable repercussions on FinOps and AI spending strategies
Future Trends in AI FinOps & Deep Learning
| Future Trend | What It Means | Potential Impact |
|---|---|---|
| Serverless GPUs & On-Demand Neural Accelerator Chips | The possibility of tapping into GPU (or specialized AI chip) power only when an inference or training job is actively running like serverless computing for CPU tasks. | – Could dramatically reduce idle costs by allowing pay-as-you-go GPU usage. – Increases flexibility for short, bursty training jobs. – Still in early experiments but looks promising. – challenges include latency during spin-up amd potential orchestration overhead. |
| Deeper Integration with MLOps & HPC Orchestration | MLOps pipelines might automatically select the cheapest or most performant GPU nodes via HPC schedulers making real-time trade-offs between cost and speed. | – Streamlines cost governance by weaving it into the development life cycle. – Potentially accelerates model iteration without drowning in hidden fees. |
| Community-Sharing of Idle Compute | A concept where organizations lease out their unused GPU capacity to other teams—like how decentralized computing once thrived in distributed projects. | – Could lead to novel revenue streams for companies with spare GPU time. – Raises questions of security, data privacy, and consistent SLAs. |
FinOps, when integrated thoughtfully into deep learning operations, can truly change the game. By monitoring costs in real-time, adopting smarter resource provisioning strategies, and cultivating a culture of financial awareness, teams no longer must treat GPU bills as an inevitable sinkhole.
By weaving FinOps Principles into the fabric of deep learning, organizations can scale AI initiatives more sustainably. It’s not about stifling experimentation—it’s about doing it with eyes wide open, ensuring that every GPU hour and gigabyte of data is used as wisely as possible. Start implementing these FinOps Framework suggestion today to ensure your AI initiatives remain innovative while staying financially viable.