




Brent Eubanks
Wayfair
This paper addresses the effects of engineering and optimization techniques for AI workloads. Optimizing workload costs while maintaining quality and performance standards is essential in any environment, but particularly challenging with AI systems because of their relative novelty and fast pace of change in this technology area.
The foundation’s FinOps for AI Working group has produced two previous papers on estimating and forecasting FinOps for AI.
In addition, if you are new to FinOps for AI the FinOps for AI Overview gives a more basic level setting of the practice of FinOps in the scope of AI.
This paper begins to address the Optimize Usage & Cost domain, specifically addressing how optimizations performed on AI workloads will impact forecasting done today. If your organization is currently managing AI workloads at scale, either in the data center, in the cloud, or in a SaaS model, addressing the benefits and challenges specific to optimizing AI workloads can help your teams improve forecasting overall.
Current best practices are presented to enhance operational efficiency, improve cost-effectiveness, and maximize business value. The analysis addresses the complexities faced by FinOps practitioners navigating AI model management, tools, and processes, offering insights and strategies to overcome these challenges.
Optimization requires a delicate balance between availability, performance, and cost efficiency, demanding a deep understanding of AI workloads and their unpredictable cost dynamics. AI workloads can vary dramatically in computational intensity and storage needs, making an uninformed approach risky and potentially leading to significant forecasting errors and wasted resources.
The paper also includes user stories from experienced AI and FinOps practitioners and provides methodologies to optimize business outcomes. The goal is to allow FinOps practitioners to exert strong control over cloud spending, preventing budget overruns and ensuring financial transparency.
By examining these user stories through our lens, this analysis serves as an indispensable primer for approaching the fast-evolving, competitive landscape of AI, where mistakes can be very costly.
The paper content is organized by Persona, beginning with Finance, then FinOps Practitioner, then Engineering. Each section addresses the perspective and activities that Persona should be looking to engage in when supporting optimization activities in the AI scope.
Following these sections are user stories illustrating some best practices. Additional content from the FinOps for AI Working Group is planned which will address more specific optimization challenges. Input from readers is welcomed by using the Make a Suggestion button above.
Understanding the TCO and quantifying the business value of AI workloads is the key to understanding when and where optimization is required. These capabilities are fundamental in managing and controlling budget variance, minimizing over-forecasting and avoiding unexpected spending in any workload, but are more critical and difficult with AI Workloads because of the lack of much historical data, still volatile market and pace of change.
Pricing trends over the last few years from major AI vendors and cloud providers show costs tend to decrease while quality and performance make significant jumps every 6-9 months.
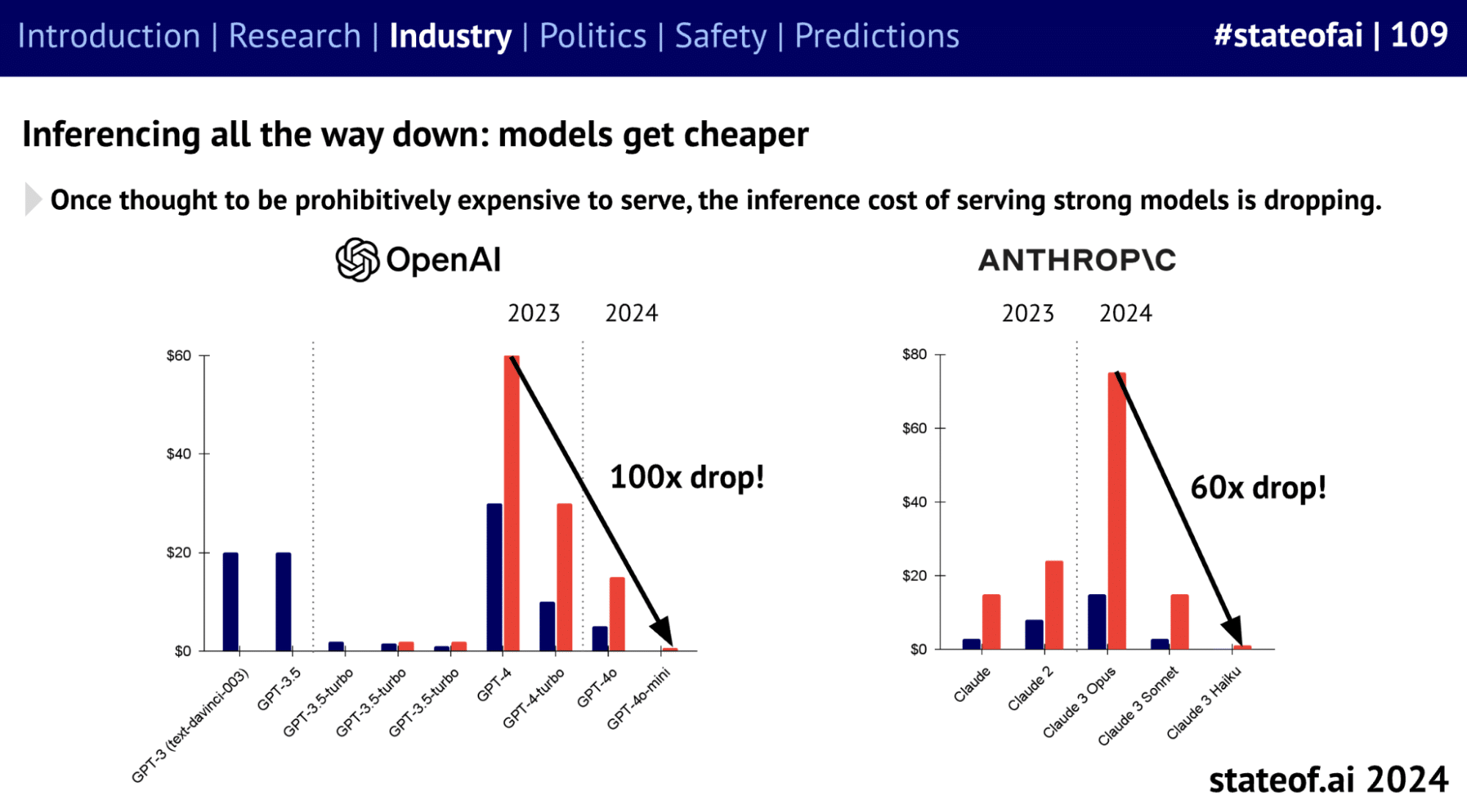
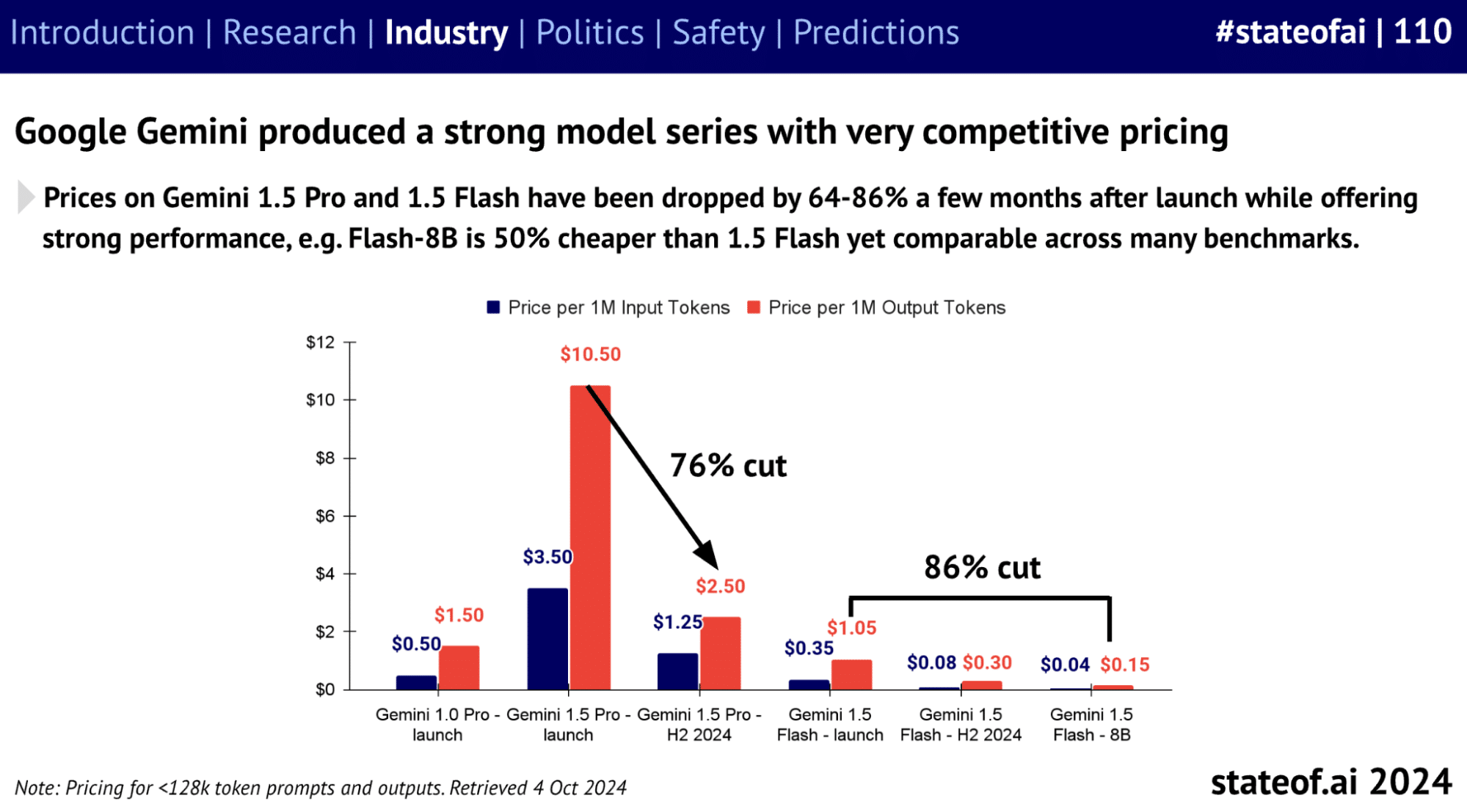
Intelligence going up over time:
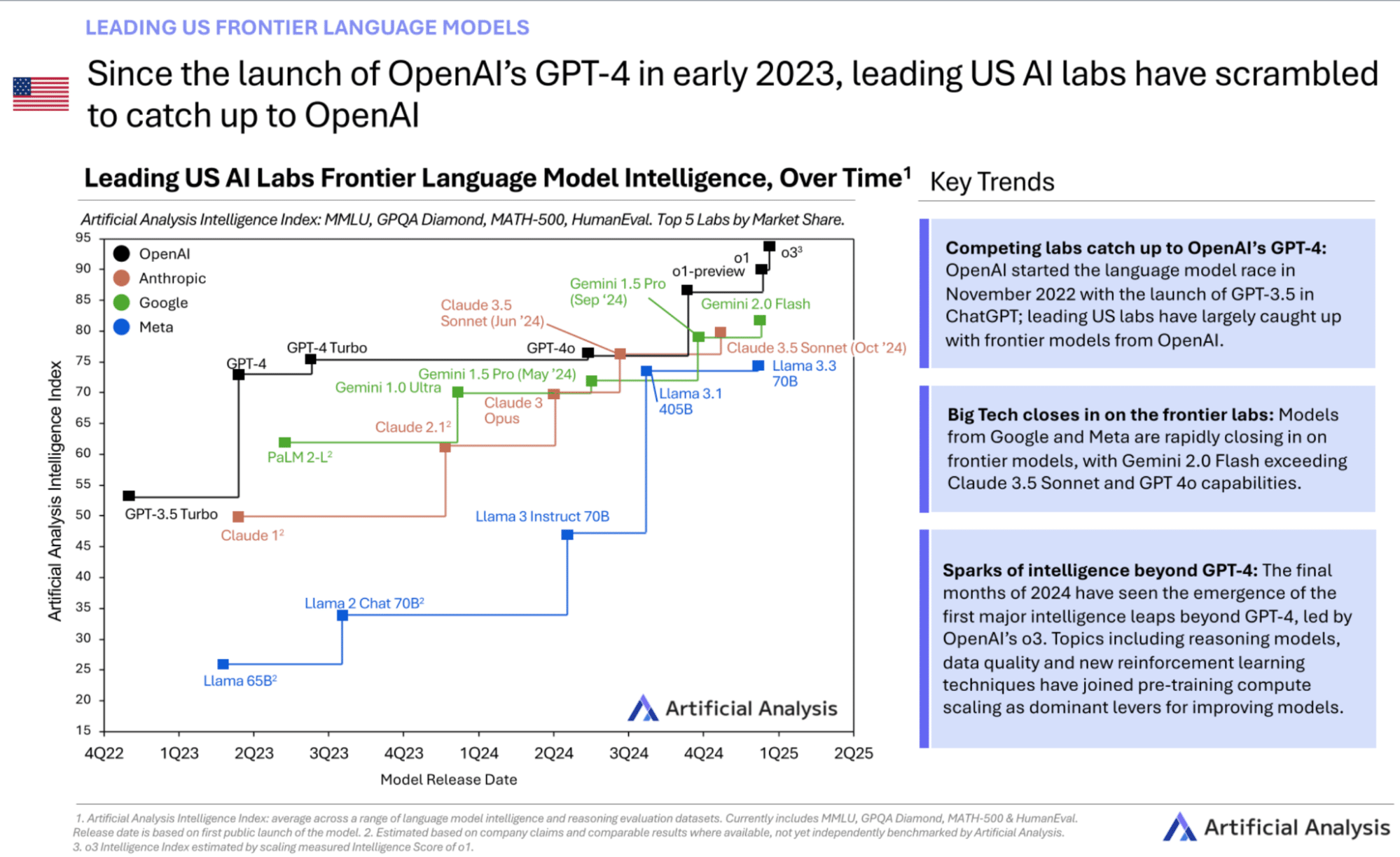
Considering these trends is essential for accurately projecting costs and understanding the impact of long-term contracts and commitments made by FinOps teams.
Finance should be identifying and focusing on the basic cost drivers of application-centric and cloud provider-centric AI implementations, understanding their cost trends, and ensuring / insisting on alignment of AI operational costs with financial value expectations. Even with limited technical knowledge of AI, Finance can drive optimization decision making.
AI systems are made up not only of novel AI-specific services, but “traditional” compute, storage, database, and networking cost elements. Driving teams to rightsizing resources to match model requirements, reducing unnecessary data transfer costs, and using existing tools to monitor cloud expenses all pay dividends. These practices form the foundation for accurate forecasting and cost-effective operations, which are crucial for maintaining a predictable financial environment in the cloud.
Financial management of AI workloads should go deeper to involve KPIs specific to those AI systems. Detailed analysis of key financial metrics like cost-per-unit-of-work to measure the value derived from AI investments. Advanced strategies such as selecting cost-effective models, reducing token usage, and optimizing workflows are essential to achieving lower costs while maintaining high performance. For organizations training their own AI models, understanding the time and cost to get to inference, or the cost tradeoffs associated with in-house training may be critical as well.
These practices, combined with robust cost visibility and governance practices, ensure that spending aligns with business objectives, prevents budget overruns, and enhances financial transparency. By implementing these techniques, Finance personas can help maximize business value and maintain tight financial control over AI spending. AI is a technology with a tremendous amount of hype and excitement, making Finance’s role more important in ensuring an organization can achieve success while not overcommitting in this competitive landscape.
The diagram below illustrates a four-step process for estimating the cost of running a custom GenAI application. AI Cost Estimation goes into more detail on this subject, this is a recap.
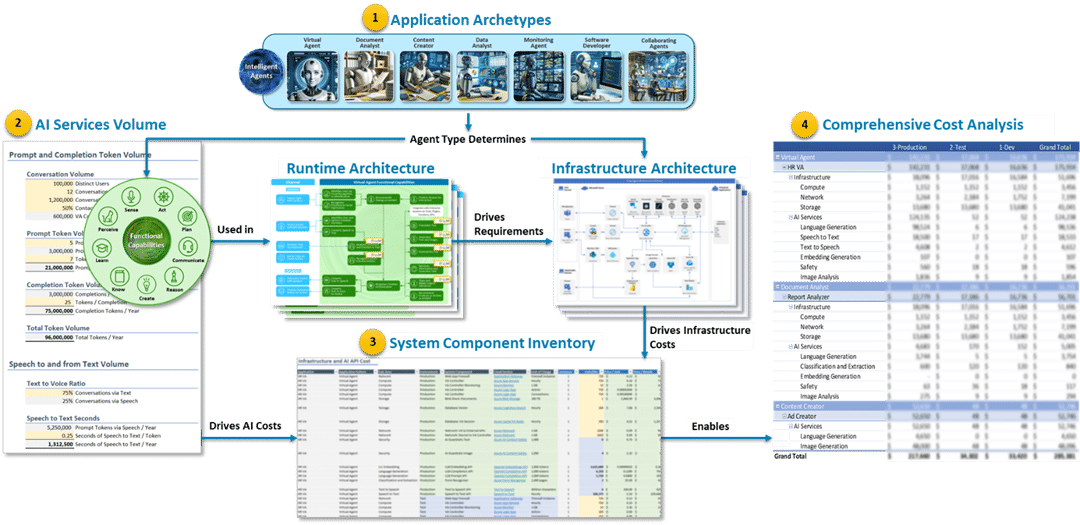
With this high-level process in mind, the next sections look at how FinOps Practitioners can identify Optimization opportunities during each step.
Understand the layers that are key for an AI application or service to run in production.

Of primary importance during this step for FinOps Practitioners is understanding the elements of the AI system that will be required, and then determining how to estimate each component according to its pricing models. Asking the right questions during this step can pay huge cost dividends during and after development. FinOps practitioners should be seeking to be involved in these discussions as early as possible.
Ensure during this step that the needs of the outcome match the capabilities of the archetype selected. There may be a strong inclination, especially as AI services are first explored, to try to get the highest possible quality, or to select models or architectures that are not required to accomplish the job at hand. A central tenet of optimization in FinOps is ensuring that organizations use only the services required to accomplish the business and technical goals, and then pay the least feasible for those services they use. Critical to push this point of view during this step.
As shown in this example, AI-specific components of the infrastructure may require forecasting using different metrics for usage than “traditional” cloud services like compute. Tokens, images, API calls, and other metrics are more common with managed AI services. The FinOps practitioner can help by understanding these metrics, explaining pricing methodologies to the organization, and ensuring that development proceeds with a clear view of what costs are likely to be.
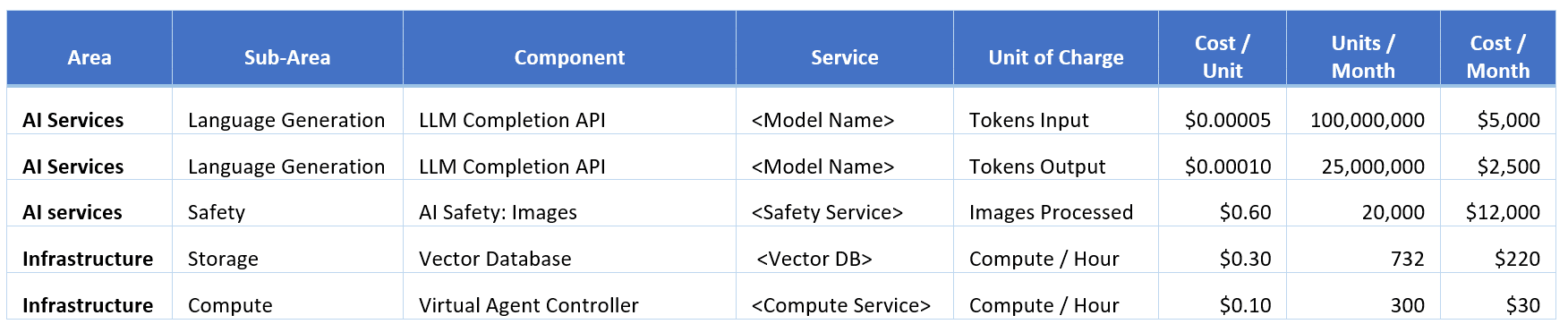
If the FinOps practitioner is working with the development teams early, alternatives for various components of the system can be identified to again ensure that the cost of all of the services required to operate the AI application are taken into account.
List and clearly identify the AI application components and understand how those costs are going to be mapped to your business.
For AI services this may be several challenges:
The connection you create between cloud resource level billing data, tags data, and any of your custom ETL data processes to map the tags to the costs will produce the baseline costs by application components data set. This establishes the first showback reports by application components with tags as primary grouping filter. Please refer to the prior forecasting paper on this for further design considerations.
Insert your company’s internal, negotiated or allocation unit rates to see the costs per month. Below is an example of the end state AI application cost analysis bringing all these items together for a cost view and will aid in better forecast accuracy.
Next you will need to determine the method to show back the costs incurred by these SKUs back to the AI application name and owners. Typically this is done with labels, projects/accounts, or tenant tag values that are applied by the workload owners or platform operations processes before deploying.
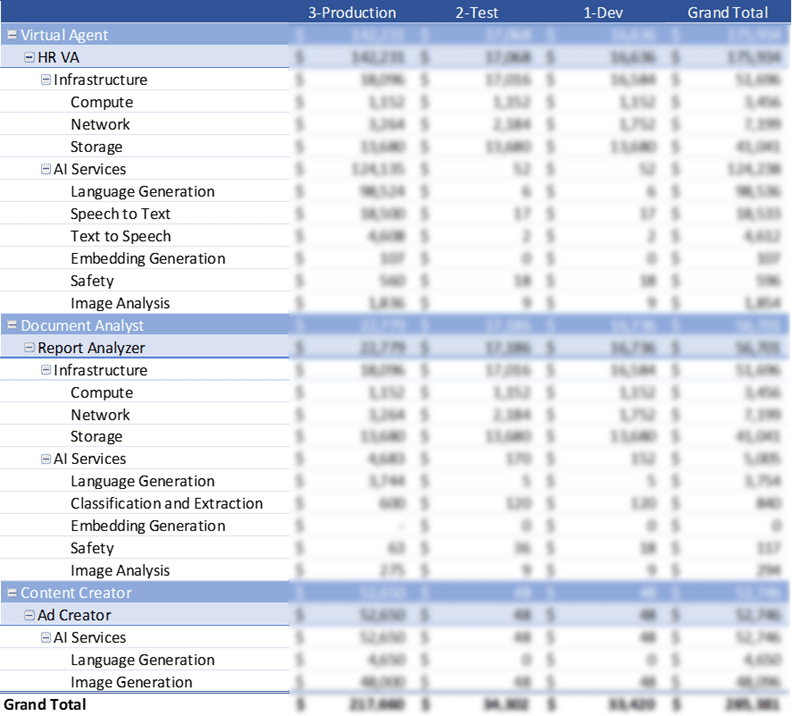
This financial and business view of AI workloads costs illustrates the potential for large cost spikes, anomalous spend, large portions of unallocated or costs with no owner are common today. The AI Forecasting paper provided a few examples of AI cost calculators to use where spreadsheets may not be the right tool for developers or for API automation goals. Where this paper is now extending those concepts to show how important the optimization factors are in AI workloads and ultimately achieve much greater forecasting accuracy.
Here is a conceptual chart to leverage when you want to understand how much each AI optimization technique contributes to reducing the spend on a major AI production workload:
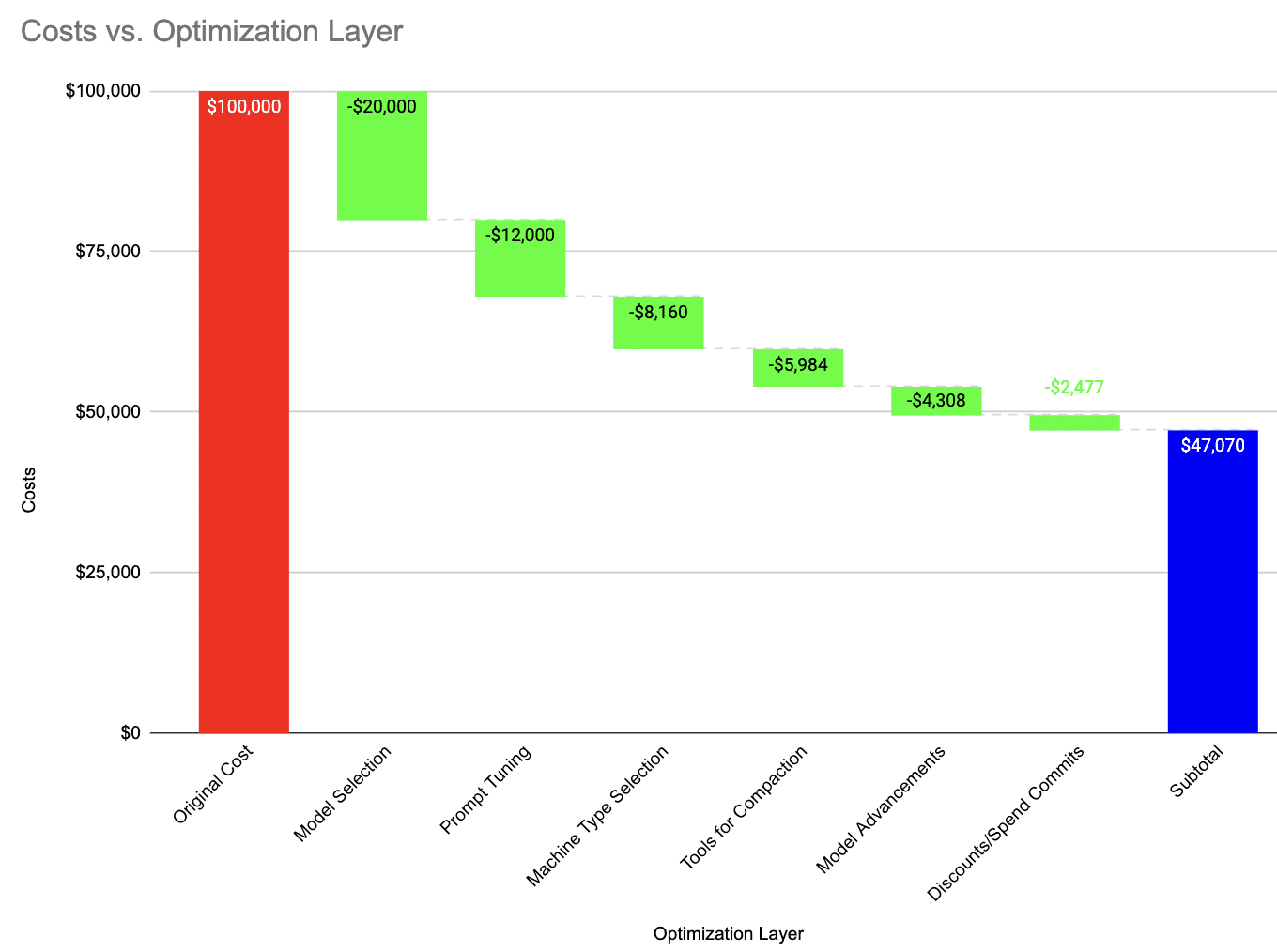
Graphic showing the potential total benefit from using a mix of these AI engineering and cost optimization tactics mentioned in this paper.
Once the costs of an AI system has been identified, the next crucial step is to compare the cost to the business value that is expected. FinOps practitioners can work here with Finance, Product and Engineering teams to ensure planned investments, taking into account likely optimization to usage or rates, is appropriate to the value expected.
FinOps Practitioners can then help to prioritize investments strategically to maximize return on investment (ROI) and business value. To assist in this process, tools like the Google Cloud FinOps team’s Generative AI Prioritization Rubric, AWS AI value chain, or Azure AI value areas can be used as a framework for evaluating and scoring AI use cases, enabling organizations to make informed decisions about which ones to pursue.
The FinOps X video for GenAI value presented additional content on this topic, and a future AI Working Group paper will address AI Value directly.
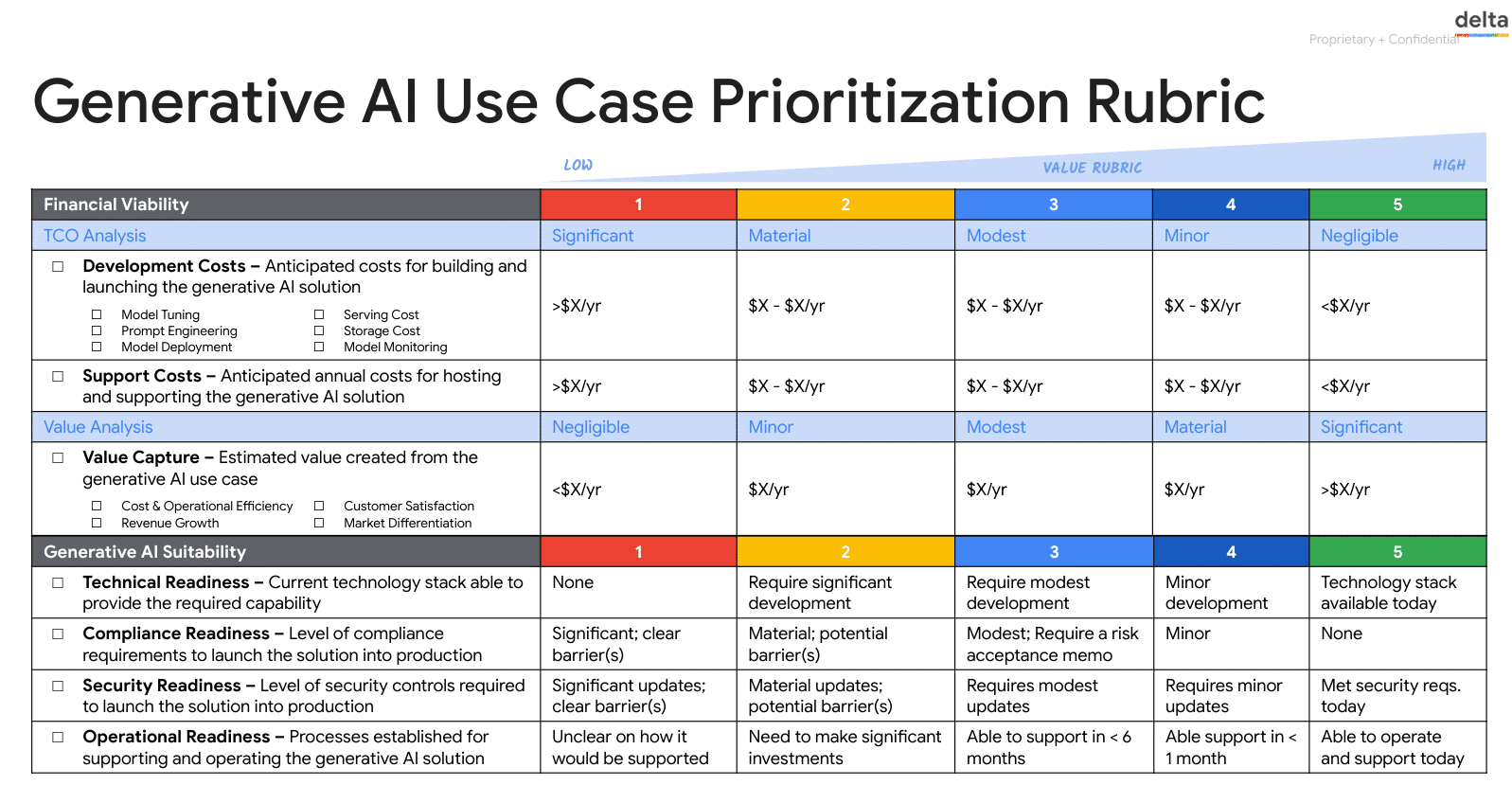
Google Cloud FinOps: Generative AI Use Case Prioritization Rubric
The FinOps for AI working group participants have contributed the following methods, approaches, and results to help engineers building AI systems better understand optimization actions that are possible for AI workloads.
These examples are presented with content suitable for both beginners or experienced practitioners, providing insights regardless of experience level. The goal is to capture a reference of the approach as a real-world example and the outcomes that were achieved. There have been quite a few highly valuable research papers and commercial articles that have covered this topic and share a common narrative that is captured in this paper.
By understanding and aggregating these various tactics, you can formulate a more comprehensive checklist of items for your organization, identifying which strategies provide the most value. This will enable you to use the best value technologies as they mature, and leverage tools, scripts, or cloud engineering design choices to greatly increase your value.
For those aiming to maximize value from AI technologies, making strategic decisions about the technology stack as early as possible is crucial. These decisions significantly impact total costs and forecast accuracy.
Optimization decisions can be made by engineers in three primary areas:
To drive continuous improvement, community engagement is essential, such as participating in platforms like arena.lmsys.org, where users can compare different AI models by voting on which provides better answers or performing side-by-side comparisons of models (e.g., current vs. latest versions) to ensure consistent or improved quality.
Methods and practices in AI systems engineering are evolving rapidly and changing constantly. This paper presents below a table of key tactics to consider for engineers optimizing AI workloads. The Cost benefits are suggested in the Benefits column. As with many FinOps concepts, the goal here is to identify opportunities for improvement to identify where action can be best directed without interfering with broader business objectives.
| Tactic | Considerations | Benefits |
| Small Parameter Count Models (SPC) | Compare models like Phi 2/3 vs. LLaMA-3 to balance cost and quality. | Cost Savings: Reduced memory usage, lower energy consumption, faster deployment times. |
| Quality Improvements: Similar or better performance, faster inference times, easier training, and optimization. | ||
| Model Selection | Choose models based on cost-effectiveness and task requirements.Programmatically with semantic router vs manual config approach | Efficiency: Potentially use different models for different parts of the workflow to optimize costs and outcomes. Semantic or smart routing is preferred tech investment over manual selection hard coded. |
| Prompt Engineering | Reduce token usage by optimizing prompts and utilizing variables. | Cost Reduction: Minimizes unnecessary token consumption and tailors model outputs to specific tasks for better results. |
| Speculative Decoding | Use low-latency draft models for a speedup in LLM inference. | Performance Boost: Up to 60% higher throughput for models like LLaMA-65B. |
| Caching – Tokens or Content | Implement caching to eliminate redundant computations. | Optimization: Reduces latency and scales efficiently, essential for production AI workloads. |
| Resource Augmentation Generator (RAG) | Send only essential data to save on token usage. | Resource Efficiency: Selective data transmission reduces token costs without sacrificing quality. |
| Sender System | Display content without additional token costs. | Zero-Token Usage: Efficient content delivery directly to users. |
| Workflow Optimization | Design workflows that operate independently, minimizing token usage to align just enough intelligence to get the task done,not over done. | Cost-Effectiveness: Strategic use of provisioned capacity and failover logic reduces overall costs.Intelligence rises and costs per IQ score is dropping. |
| Experimentation with Sample Data | Quickly validate assumptions and identify the best modeling approach. Auto Judge and/or Human feedback in loop | Low-Cost Iteration: Use sample data to refine models before scaling up. |
Understanding cloud pricing models and effectively managing resources are pivotal for optimizing AI workloads. Below are infrastructure-centric strategies to help achieve these goals:
| Strategy | Considerations | Benefits |
| Cloud Pricing Models | Familiarize with pricing structures of AWS, GCP, Azure, etc. | Cost Awareness: Identify key cost drivers like compute and storage costs. |
| Right-Size Resources | Match AI model requirements to appropriate cloud instance types. | Resource Efficiency: Avoid over-provisioning by adjusting instance sizes based on utilization. |
| Optimize Data Management | Keep data close to compute resources to minimize transfer costs. | Cost Reduction: Implement data lifecycle management to archive or delete unused data. |
| Choose Cost-Effective AI Services | Evaluate cloud-native AI/ML services versus DIY infrastructure. | Cost Savings: Leverage pre-trained models and transfer learning to reduce training expenses. |
| Optimize Model Training | Experiment with model architectures and hyperparameters for cost-effectiveness. | Efficiency: Use spot instances or preemptible VMs for non-critical workloads. |
| Optimize Inference | Implement techniques like caching and batching to minimize token usage. | Cost Optimization: Choose the most cost-effective inference deployment options, including serverless and containers. |
| Cost Visibility and Governance | Set up monitoring and alerting to identify cost anomalies. | Accountability: Implement FinOps practices to align spending with business objectives. |
| Treat Instances as Ephemeral | Automate instance shutdowns to reduce costs when idle. | Cost Control: Utilize preemptible/spot VMs for long-running experiments, reducing expenses. |
Utilizing specialized AI tools can significantly enhance the efficiency and cost-effectiveness of AI operations. Below is a selection of tools designed to optimize token usage and cloud costs:
| Tool | Key Benefits | Optimization Impact |
| RouteLLM | Reduces AI costs by routing queries to the most suitable LLM. | Cost Savings: Up to 85% cost reduction by handling simpler queries with less expensive models. |
| vllm | Provides improved inference throughput and reduced memory usage. | Performance: Up to 3-6x inference speed improvement with reduced memory usage. |
| LLMLingua | Compresses prompts for faster inference and reduced costs. | Efficiency: Achieves up to 20x compression with minimal performance loss, enhancing speed and reducing token usage. |
| Tiktoken or Openlit | Estimates token usage and costs, enabling prompt optimization. | Cost Control: Predicts and reduces token costs by 10-30%. |
| Semantic Kernel | Monitors token usage, allowing for targeted optimizations. | Cost Reduction: Identifies inefficient API usage patterns, reducing token costs by 15-40%. |
| SkyPilot | Automates cloud instance selection for cost-effective AI workloads. | Cost Savings: Reduces cloud compute costs by 20-50% through dynamic resource adjustment. |
| JetStream | Optimizes data management to minimize transfer and storage costs. | Cost Efficiency: Reduces data-related costs by 25-60% by optimizing data locality and lifecycle management. |
| ML Anomaly Detection | Detects cloud cost spikes and anomalies using AI-powered monitoring. | Cost Control: Reduces cloud costs by 15-35% through real-time alerts and recommendations. |
Using these strategies and tools, organizations can optimize the costs of running AI workloads while maintaining high standards of quality and performance. This approach not only reduces expenses but also enhances the efficiency and effectiveness of AI-driven operations.
This section contains user stories from members of the FinOps for AI Working group in late 2024 and early 2025. They are intended as illustrative examples of how companies managing AI costs in various ways have used some of the above optimization techniques to understand and optimize their costs.
In the evolving landscape of cloud cost management, migrating workloads to more efficient hardware architectures, such as ARM-based instances, is an effective strategy for achieving cost savings. This approach, while not exclusive to AI workloads, can provide a relatively straightforward way to reduce costs without sacrificing performance. Depending on the instance types, switching to ARM instances can result in savings of anywhere between 10% and 20%.
As part of our continuous efforts to refine our cost optimization strategies and enhance performance, our team undertook a structured migration of key AI/ML workloads from x86 AMD & Intel AWS instances to ARM-based Graviton 2 & 3 instances. We divided this migration into three main workloads, each presenting unique challenges and opportunities. Our primary focus was to realize cost savings while either maintaining or improving performance metrics. Additionally, we aimed to maximize the value of our existing commitments, such as Reserved Instances and Savings Plans.
In this section, we share our approach, the outcomes, and the key insights we gained from these migrations, offering valuable lessons for those looking to deepen their expertise in FinOps and AI cost management.
We wanted to reduce costs for our AWS EMR workload, used for custom ML models building, by migrating from x86 to ARM instances, without sacrificing performance. This simple instance type change in our Terraform configuration allowed us to move 40% of the workload to Graviton with a 14% cost reduction while maintaining similar performances. We only migrated a portion of this workload as we are about to phase out some of it.
| Phase | Cost example | Commitments consumption | Performance |
| Baseline (x86) | $10,000 | 100% | |
| Migration (ARM) | $8,600 (-14%) | 100% | Similar |
We needed to carefully migrate our performance-tuned x86 application to ARM to take advantage of cost savings, while ensuring performance meets requirements. With substantial engineering effort, we added ARM support to our application and started migration of the workload achieving a 15% to 20% cost reduction so far, with P90 performance actually improving by 16%. Here, we anticipate a range of cost savings as this workload is currently operating on a mixture of AMD and Intel instances. We will be able to utilize both Graviton 2 and 3 based on the performance needs.
| Phase | Cost example | Commitments consumption | Performance |
| Baseline (x86) | $20,000 | 100% | |
| Migration (ARM) Ongoing | Between $16,000 (-20%) and $17,000 (-15%) | 100% | P90 improved 16% |
We aimed to optimize our core AI/ML workload of model serving, by migrating from x86 to ARM-based Kubernetes nodes. The initial 1:1 instance migration is expected to yield 15% cost savings with a relatively straightforward migration due to the Python-based workload. However, further optimizations leveraging ARM’s performance benefits could allow packing more workloads per node for compounding cost reductions. Here, we anticipate savings of 15% as we transition from using Intel CPUs to Graviton 3 CPUs. Although the Graviton 3 CPUs come at a higher cost than the Graviton 2 due to our performance needs, we expect to see increased efficiency and cost benefits in the long run.
| Phase | Cost example | Commitments consumption | Performance |
| Baseline (x86) | $20,000 | 100% | |
| Projected Migration (ARM) | $17,000 (-15%) | 100% | Improved |
| Projected Optimization | TBD but we could expect another 10% | TBD | Improved density |
| Workload | Cost Reduction | Performance Impact | Challenges | Results |
| EMR | 14% | Similar performance | Easy migration using AWS Managed Service | 14% cost savings achieved with minimal effort |
| Custom | 15% to 20% | P90 performance improved 16% | Significant effort due to custom nature | Effort expected to pay off within months |
| AI Core | 15% | Expected better performance | Initial migration easy, further optimizations possible | Immediate and future cost savings anticipated |
This migration to ARM not only drives substantial cost savings across our AI/ML workloads but also unlocks performance optimizations that will allow us to further consolidate and save by taking full advantage of ARM’s enhanced capabilities for these modern workload types.
What does it look like to optimize the token usage of a generative AI system in practice? A simple yet illuminating example comes from the financial services industry: a Finops Foundation member partnered with a cloud platform engineer who was responsible for understanding the Identity and Access Management (IAM) policies in use at the organization. Unfortunately there were more than 60,000 custom IAM policies, each with multiple versions available. The expertise to read and understand these policies was hard to come by and expensive to pay for. The time to review all of them was estimated to take years. The cloud platform engineer was stuck and unable to explain the policies they needed each person at the organization to understand.
Generative AI was considered as an option to comprehending these policies at scale. While it was not perfect, it made a sizable impact on the amount of human work required. Here was the idea:
The process worked great but soon the Finops Foundation member discovered their process was rather expensive: some IAM policies could change every day while others could spend years without being modified. By running all policies through the process once a week, the cost was beginning to spiral out of budget.
The solution was to use a classic cost savings technique for large distributed systems: hashing and caching. The process was modified as follows:
This change had an immediate impact on token usage for the AI workload: the Finops Foundation member reported a 99% reduction in on-going token usage for this workload. If there was no modification to the policy, then there was no need for GenAI to reevaluate it. . That reduction enabled the use of their monthly token budget for other big problems, expanding the capacity of their team by augmenting their workforce with more GenAI tools.
This is a simple but powerful example of how traditional software optimization techniques like hashing and caching can play a huge role in GenAI workload optimization. When discussing GenAI costs with your application teams, ask about their performance or operational optimizations they’ve considered but not yet implemented. Those ideas can often directly lower GenAI costs and expand the possibilities for future GenAI workloads.
Closed Source LLMs
Using a blend of dedicated and shared capacity will reduce cost-per-token.
Examples based on actual usage over a 30-day period
Text-based LLM application workload type where capacity is the primary driver to deliver the expected revenues.
All production traffic using dedicated/provisioned capacity
The cost per token is 33% higher than the shared capacity rate.
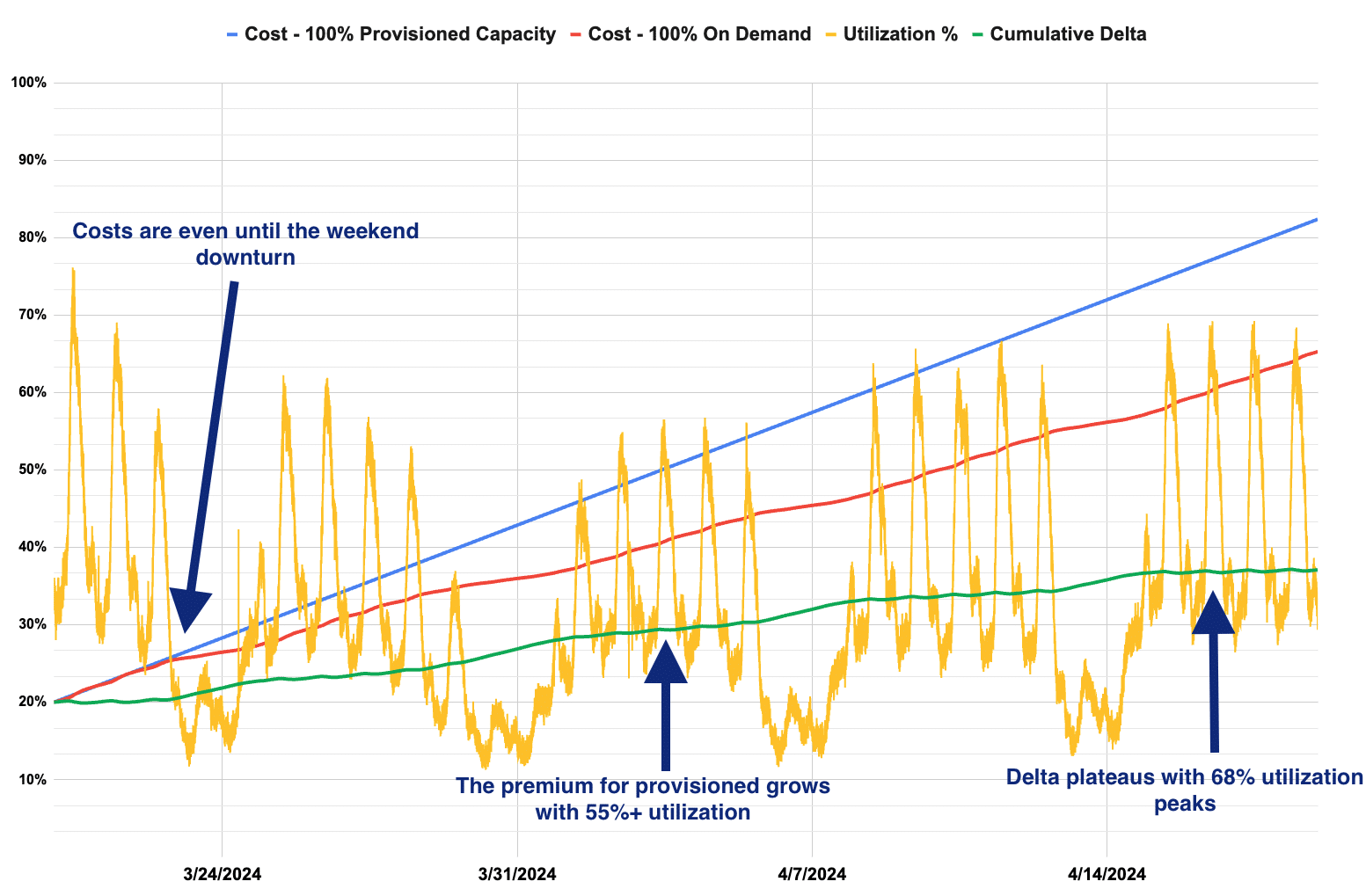
Flexible Performance Needs
<1% of all requests reverted to shared capacity
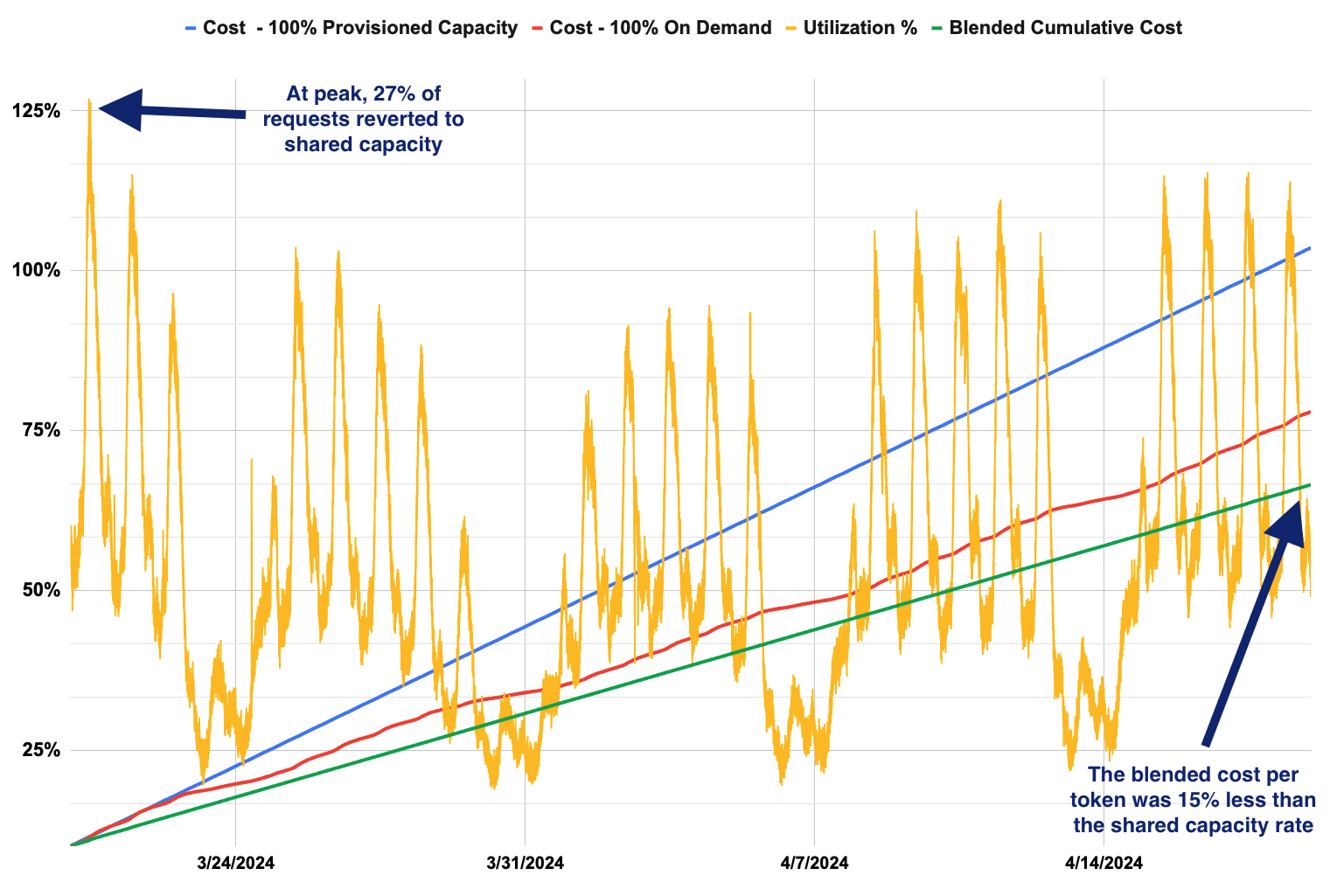
Rate Optimization
<13% of all requests reverted to shared capacity
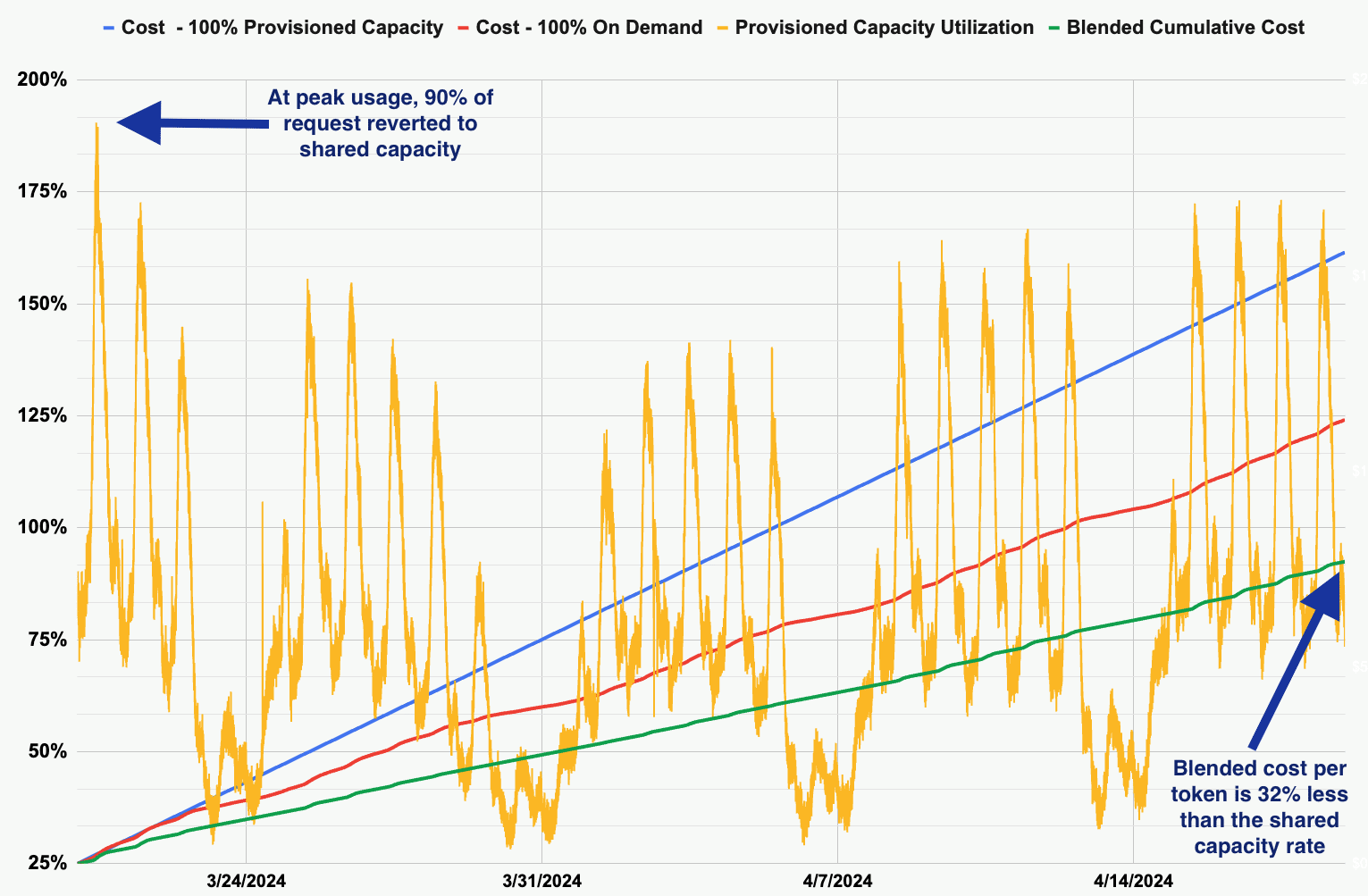
The quality of AI in data analysis is a critical concern for organizations. One key issue is accuracy, as models may produce incorrect results due to poor training data or algorithmic limitations. This can have dire consequences, as AI-generated insights are increasingly used to make important decisions. Another concern is hallucinations, where AI generates content that appears plausible but is factually incorrect. This can lead to significant risks in decision-making processes.
The rapid pace of change in AI models further complicates the issue. As models are constantly being improved and updated, organizations need to ensure that they are using the latest versions. This can be a resource-intensive process, as it requires comprehensive retesting and validation. Additionally, transitioning to new models or implementing new optimization scripts/tools can be costly, as even minor changes can have far-reaching effects.
This “change one thing, changes everything” phenomenon often necessitates the use of human verification or additional AI systems for ongoing quality assurance. This adds layers of complexity and expense to AI implementations. Given the high stakes involved, it is essential for organizations to have a robust process in place to verify and validate the quality of their AI models. This includes regular monitoring and updating of models, as well as comprehensive testing and verification. By investing in quality assurance and adopting cloud FinOps best practices, organizations can mitigate the risks associated with AI and ensure that they are using AI technology effectively and maximize the financial investments.
By understanding some of the basic types of optimizations available to manage costs and their potential impact on cost, businesses using AI can achieve more accurate forecasting due to mature planning. This will lead to more value (work) per AI dollar spent on GenAI services.
Accurately budgeting for AI workloads is a multifaceted challenge given the dynamic nature of AI projects and the rapid evolution of the technology. Both over-budgeting and under-budgeting can have significant implications. The risks associated with inaccurate budgeting include misrepresentation of required funds, project delays or even complete halts, compromised project quality, wasted resources, and reduced ROI.
In User Story #2, consider a scenario where hashing and caching weren’t utilized. As budget season approached, the high cost of the AI workload might have led to its discontinuation. This could have resulted in severe implications, including the loss of valuable insights, missed opportunities, and competitive advantages. In the worst-case scenario, the AI workload could have been budgeted as is and then optimized. This would have provided justification for overspending to the CFO, potentially damaging trust and confidence in AI initiatives.
By deploying hashing and caching, the organization significantly reduced the cost of the AI workload, making it more affordable and sustainable. This allowed the organization to continue leveraging the benefits of the AI model while ensuring proper security and compliance.
GenAI is one of the most impactful technologies invented, and it is contributing massive value to enterprises. By leveraging the financial investment approach, forecasting methods outlined in prior papers (how to forecast AI, and AI cost estimation examples), the agent, model and infrastructure optimization methods mentioned above, FinOps, Engineering, and finance teams can collaborate and plan effectively to deliver higher business value, reduce costs and achieve forecasting accuracy goals for the business. Optimization efforts can significantly reduce costs, shorten response times, aid in accurate financial planning and ultimately maximize business outcomes.
FinOps practitioners should be driving the conversations among the finance and engineering teams to ensure that these topics are being planned and included into their cloud spend management processes as an advisory service for the business.
Thanks to the following people for their contributions and work on this Paper:
We’d also like to thank our contributors, Alireza Abdoli, Andy Panakof, David Lambert, and Sean Stevenson. We’d also like to thank our FinOps Foundation staff, Rob Martin, Andrew Nhem, and Samantha White.




